ChatGPT的训练数据
ChatGPT是由OpenAI开发的一种大型语言模型,基于GPT(Generative Pre-trained Transformer)架构。它的训练数据来源广泛,包括:
-
互联网文本:ChatGPT从大量的互联网文本中学习,包括维基百科、新闻网站、社交媒体、论坛和其他开放的网络资源。通过这种方式,它能获取到广泛的知识和多样的语言风格。
-
书籍和文献:为了提升模型的深度和广度,训练数据还包括各种书籍和学术文献。这使得模型能够理解复杂的概念和专业术语。
-
对话数据:为了增强对话能力,ChatGPT的训练过程中也包含了大量的对话数据。这些数据帮助模型学习如何理解上下文,生成连贯且自然的对话内容。
-
其他来源:除了以上主要来源,训练数据还可能包含其他类型的文本数据,如剧本、产品描述、代码文档等,以确保模型在多种情境下都能表现出色。

ChatGPT的模型架构
ChatGPT基于Transformer架构,这是一种非常强大的神经网络架构,主要由以下几个关键部分组成:
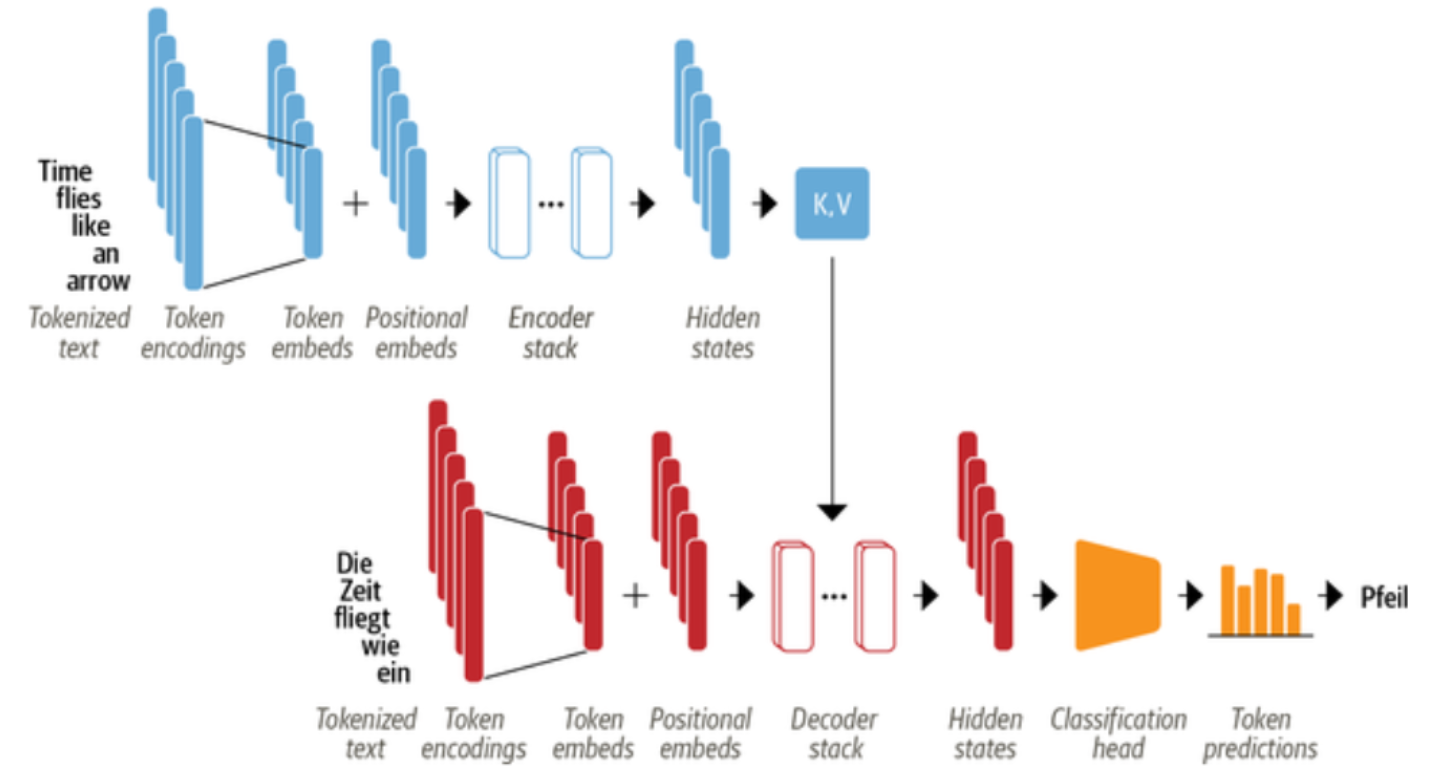
编码器(Encoder)和解码器(Decoder)
Transformer模型最初是由编码器和解码器组成的双结构,但GPT只采用了其中的解码器部分。解码器能够逐步生成文本,并且在生成每个单词时,都能考虑到之前生成的所有单词。
- 编码器:将输入的标记序列转换为嵌入向量序列,通常称为隐藏状态或上下文。
- 解码器L使用编码器的隐藏状态来迭代生成一个标记的输出序列,每次一个标记。
编码器和解码器本身是由下面几个组件组成的:
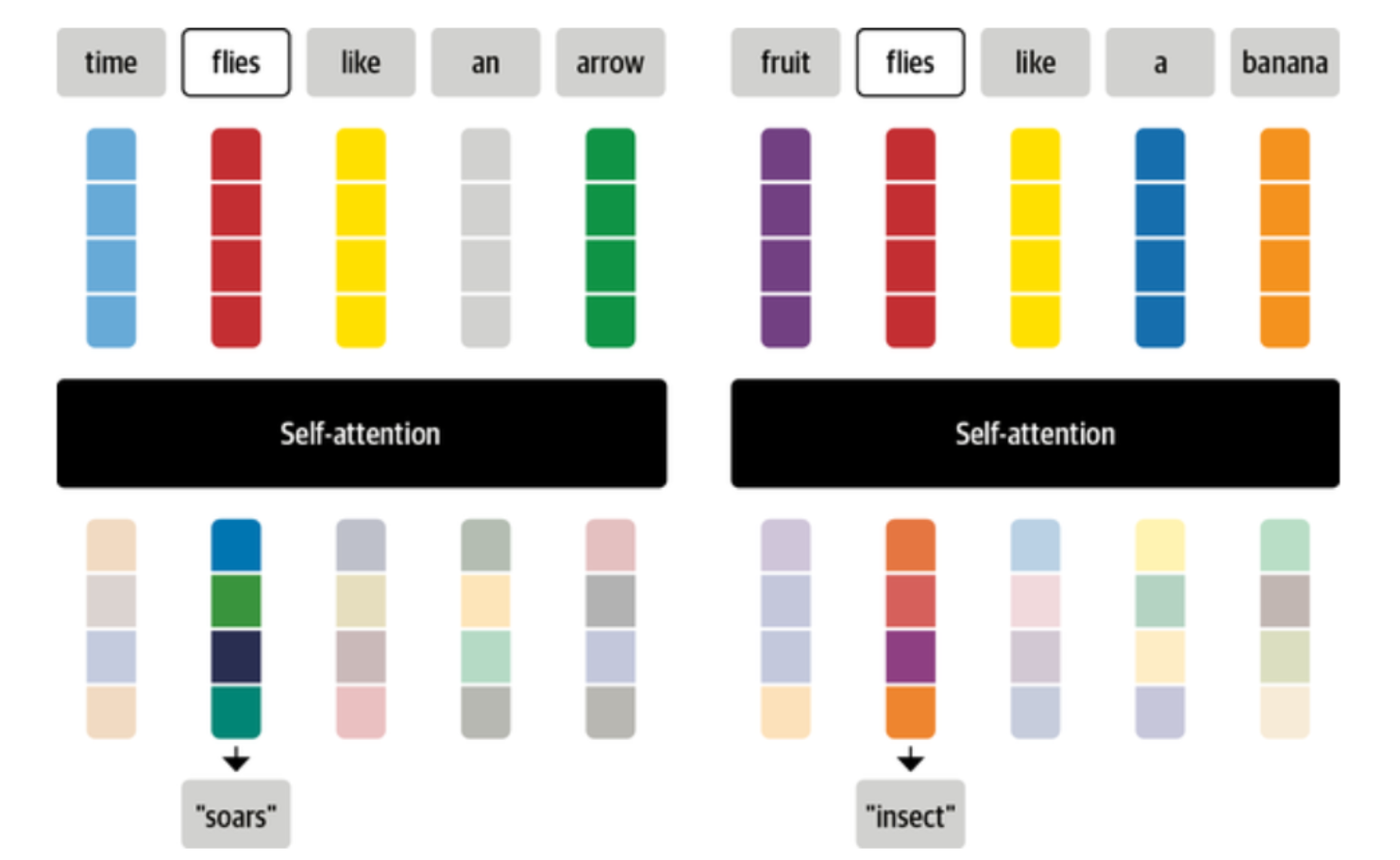
自注意力机制(Self-Attention Mechanism)
这是Transformer的核心技术之一。自注意力机制允许模型在生成每个单词时,都能参考输入序列中的所有其他单词。这使得模型能够理解并生成具有全局一致性和连贯性的文本。
注意力是一种机制,它允许神经网络为序列中的每个元素分配不同的权重或 "注意力"。
考虑一下当你看到 "苍蝇 "这个词时,你会想到什么。你可能会想到恼人的昆虫,但如果给你更多的上下文,比如 "时间像箭一样飞逝",那么你会意识到 "飞 "指的是动词。同样地,我们可以通过以不同的比例组合所有的标记嵌入来创建一个包含这种语境的 "苍蝇 "表示法,也许可以给 "时间 "和 "箭 "的标记嵌入分配一个较大的权重wji。以这种方式产生的嵌入被称为语境化嵌入,并且早于ELMo等语言模型中Transformers的发明。语言模型中的Transformers,如ELMo。下图是这个过程的示意图,我们说明了根据上下文,"苍蝇 "的两种不同表现形式是如何通过自注意力产生的。
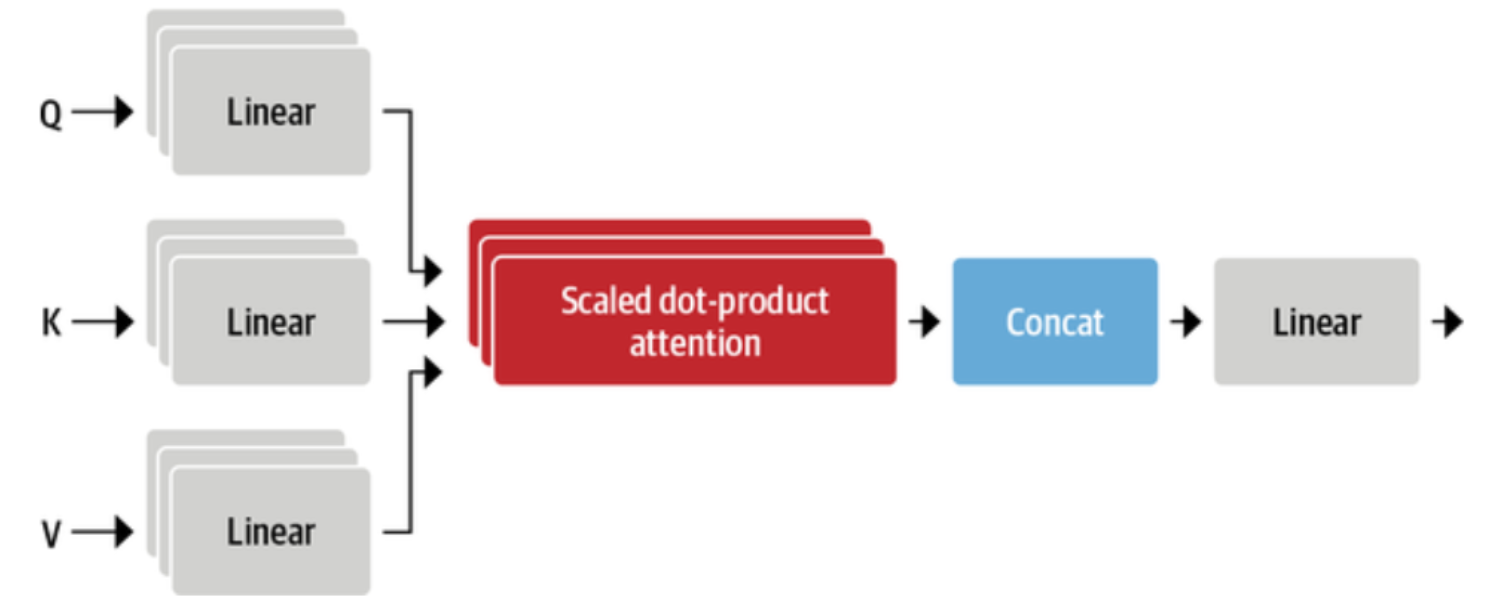
多头注意力(Multi-Head Attention)
在自注意力机制中,Transformer模型采用多头注意力技术。这意味着模型在不同的子空间中并行计算注意力分数,使得它能够捕捉到输入序列中的不同方面和细节。
在实践中,自注意力层对每个嵌入物进行了三个独立的线性转换,以生成查询、键和值向量。这些变换对嵌入进行投射,每个投射都有自己的一套可学习的参数,这使得自注意力层能够注意力序列的不同语义方面。事实证明,拥有多组线性投射也是有益的,每组投射代表一个所谓的注意头。
有了几个头,模型就可以同时注意力几个方面了。例如,一个头可以专注于主语与动词的互动,而另一个头则可以找到附近的形容词。显然,我们并没有将这些关系手工制作到模型中,它们完全是从数据中学习的。如果你熟悉计算机视觉模型,你可能会发现它与卷积神经网络中的过滤器很相似。其中一个过滤器负责检测人脸,另一个负责在图像中寻找汽车的车轮。
前馈神经网络(Feed-Forward Neural Networks)
在每个解码器层中,自注意力机制之后还会有一个前馈神经网络。这些网络能够进一步处理和转换数据,增强模型的表达能力。
编码器和解码器中的前馈子层只是一个简单的双层全连接神经网络,但有少许不同:它不是把整个嵌入序列作为一个单一的向量来处理,而是独立地处理每个嵌入物。由于这个原因,这个层通常被称为位置前馈层。你也可能看到它被称为核大小为1的单维卷积,通常由具有计算机视觉背景的人使用(例如,OpenAI的GPT代码库使用这种命名法)。文献中的一个经验法则是,第一层的隐藏大小是嵌入大小的四倍,最常使用的是gelu激活函数。这是内存占用最大的部位,也是扩大模型规模时最常扩展的部分。
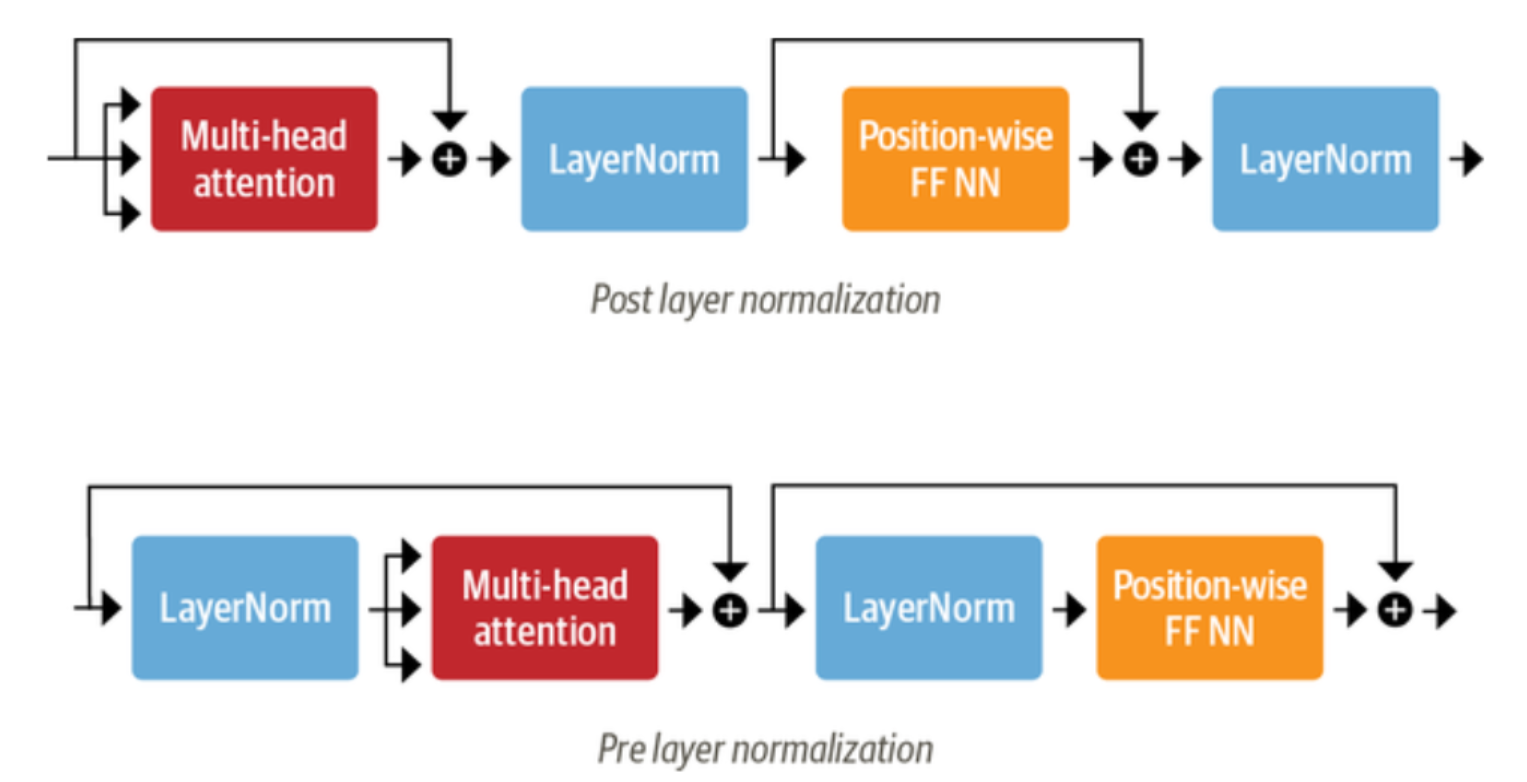
层归一化(Layer Normalization)和残差连接(Residual Connections)
这些技术用于稳定训练过程,并提高模型的训练效率和性能。层归一化可以标准化输入数据,而残差连接则允许信息在层与层之间有效传递。
层后归一化 这是Transformer论文中使用的安排;它将归一化层置于残差连接之间。这种安排对于从头开始训练是很棘手的,因为梯度可能会出现偏差。出于这个原因,你会经常看到一个被称为学习率预热的概念,在训练过程中,学习率从一个小值逐渐增加到某个最大值。 层预归一化 这是在文献中发现的最常见的安排;它将归一化层放在残差连接的跨度内。这在训练中往往更稳定,而且通常不需要任何学习率预热。
ChatGPT能够在生成对话内容时表现出卓越的流畅性和连贯性。每次生成文本时,模型都会考虑到上下文信息,并使用自注意力机制来确保生成的内容具有高质量的语义一致性。
国内怎么使用ChatGPT?
在中国国内直接订阅OpenAI的GPT Plus服务可能会遇到一些困难,因为OpenAI的服务在中国的访问存在限制。如果你想要在国内使用ChatGPT,可以参考普通的GPT会员升级为GPTPLUS使用GPT-4或GPT-4o要什么条件。
ChatGPT系列文章




文章评论