拉链表是数据仓库中特别重要的一种方式,它可以保留数据历史变化的过程,这里分享一下拉链表具体的开发过程。
维护历史状态,以及最新状态数据的一种表,拉链表根据拉链粒度的不同,实际上相当于快照,只不过做了优化,去除了一部分不变的记录,通过拉链表可以很方便的还原出拉链时点的客户记录。
这里用商品价格的变化作为例子,具体的开发过程要按实际的来,不能照搬代码,编程重要的是了解背后的思路和原理,而不是ctrl+c和ctrl+v。那对我们学习提升的帮助有限,虽然可能对完成工作的效率帮助很大。
在开始介绍之前,这里的数据仓库的环境是HIVE。
首先看看原始的数据:
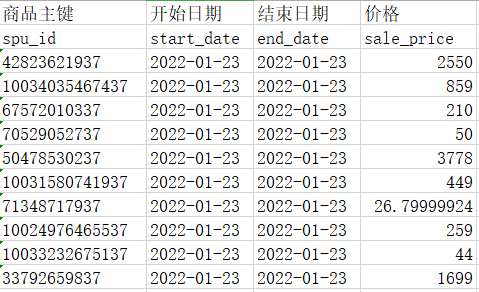
可以看到,原始的数据是每一个商品,一条记录,每一个商品,只保留最新的价格信息。这里的拉链表,我们做到天粒度的。
我们这里的思路是这样的,将最新的商品记录插入历史拉链表中,然后我们通过HIVE的窗口行数,按照end_date排序,然后分别取下一条的sale_price和end_date,然后再判断本条的价格和下一条的价格是否相等,如果是一样的,那么就把end_date改为下一条的end_date,最后做去重处理,然后就得到我们想要的数据了。
说了这么多,我觉得还是把sql贴出来会好一些,代码是最好的语言。
talk is cheap,show me the code。
-- 商品原始表这里取名goods_table
select spu_id,
min(start_date) as start_date,
end_date as end_date,
sale_price
from
(select spu_id,
start_date,
if(sale_price = lead_sale_price,lead_end_date,end_date) as end_date,
sale_price
from
( select spu_id,
start_date,
end_date,
sale_price,
lead(sale_price,1,null) over(partition by spu_id order by end_date) as lead_sale_price,
lead(end_date) over(partition by spu_id order by end_date) as lead_end_date
from goods_table ) t) t
group by spu_id,
end_date,
sale_price ;根据上面的代码,跑出来的,就是我们想要的拉链表的数据了,看看最后的效果。

使用这种方式即可以记录历史,可以最大程度的节省存储,不会产生过多的冗余。
需要数据仓库资料可以点击这个领取数据仓库(13)大数据数仓经典最值得阅读书籍推荐
参考资料:
- 数据仓库(01)什么是数据仓库,数仓有什么特点
- 数据仓库(02)数仓、大数据与传统数据库的区别
- 数据仓库(03)数仓建模之星型模型与维度建模
- 数据仓库(04)基于维度建模的数仓KimBall架构
- 数据仓库(05)数仓Kimball与Inmon架构的对比
- 数据仓库(06)数仓分层设计
- 数据仓库(07)数仓规范设计
- 数据仓库(08)数仓事实表和维度表技术
- 数据仓库(09)数仓缓慢变化维度数据的处理
- 数据仓库(10)数仓拉链表开发实例
- 数据仓库(11)什么是大数据治理,数据治理的范围是哪些
- 数据仓库(12)数据治理之数仓数据管理实践心得
- 数据仓库(13)大数据数仓经典最值得阅读书籍推荐




文章评论